How to scrape stock upgrades and downgrades from Yahoo Finance
- Dec 2, 2019
In this blog post I’ll show you how to scrape stock upgrade and downgrade data from Yahoo Finance using Python, Beautiful Soup, json, and a bit of regular expression magic.
This technique can be applied to any stock symbol on Yahoo Finance, but for this blog post we’ll be scraping data for Apple (AAPL).
I’ll be guiding you through the process, describing my thought processes and techiques, and if you follow along, by the end of this blog post, you’ll have extracted stock upgrade and downgrade data in a Pandas dataframe which will look something like this:
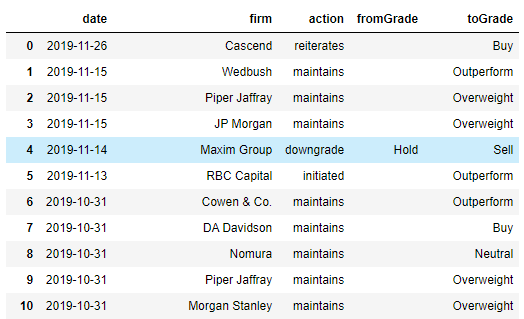
From there, you can easily export the data into an Excel file, or if you’re a more advanced Python user, host the code in a Web API which can be accessed by Google Sheets, or your own custom code.