In this blog post I’ll show you how to scrape Income Statement, Balance Sheet, and Cash Flow data for companies from Yahoo Finance using Python, LXML, and Pandas.
I’ll use data from Mainfreight NZ (MFT.NZ) as an example, but the code will work for any stock symbol on Yahoo Finance.
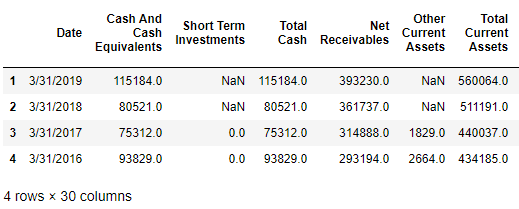
The screenshot below shows a Pandas DataFrame with MFT.NZ balance sheet data, which you can expect to get by following the steps in this blog post:
After taking you step by step on how to fetch data from the balance sheet, I’ll show you how to generalise the code to also generate a DataFrame containing data from the Income Statement, and Cash Flow statement.
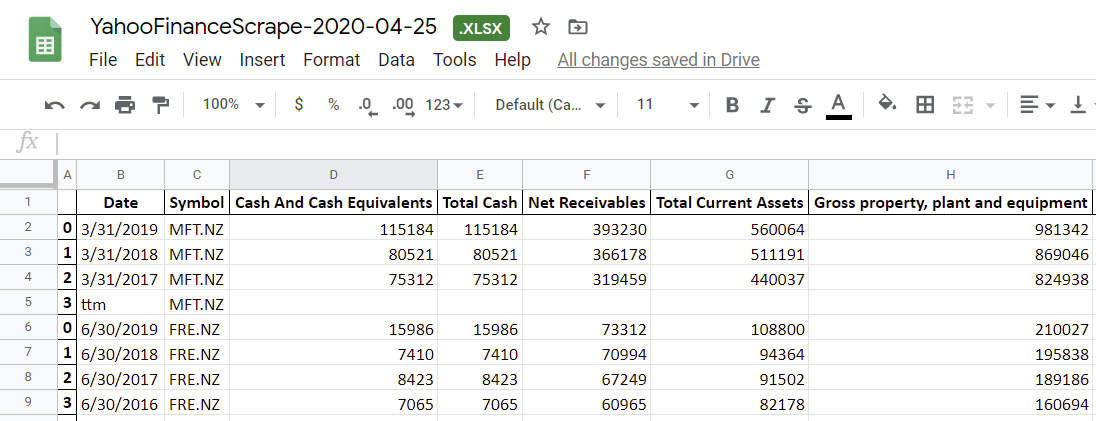
After creating the Pandas DataFrames, I’ll then show you how to scrape data for multiple symbols, and finally, export everything to an Excel file, so you’ll have output that looks something like this:
This post was last updated in April, 2020.
Prior to October, 2019, Yahoo Finance conveniently had all this data in a regular HTML table, which made extracting the data super easy. Since then, they’ve updated the page with a new structure, which was a wee bit tricker to get the data from. Fortunately, it’s still possible. Read on to find out how.