AWS Solution Architect Associate Exam Study Notes: EC2 (Elastic Compute Cloud), and Lambda
- Oct 12, 2017
These notes were written while working through the A Cloud Guru AWS Certified Solutions Architect - Associate online course. These notes are partly from the videos, and also from various other online sources. Primarily, they’re notes for me, but you might find them useful too.
Since the AWS platform is changing so quickly, it’s possible that some of these notes may be out of date, so please take that into consideration if you are reading them.
Please let me know in the comments below if you have any corrections or updates which you’d like me to add.
This post was last updated in March, 2019.
EC2 (Elastic Compute Cloud)
It’s important to know EC2 and EBS inside out as they are covered heavily in the exam.
Instance types:
Remember instance types for the exam.
| M | General Purpose i.e. app server (default) |
| T | Micro instances - Low cost, general purpose, web servers |
| C, D, I | CPU/IOPS optimised, good for memory intensive compute |
| R, X | Memory optimised |
| G, P | GPU |
| F | FPGA - Field Programmable Gate Array, for hardware acceleration of code |
Useful mnemoic: Dr Mc Gift Px
Instance Options
- On Demand Instance - pay a fixed rate per hour. Good for apps where compute needs scaling up/down - i.e. usage might increase 10x during certain hours of the day, or certain times of year.
- Spot Instance - available via bidding against other customers.
- Can be extremely cheap
- Can be terminated by you OR AWS at any time
- Best for jobs which can be terminated at any time i.e. certain types of batch processing
- Not charged for partial hour if your instance is terminated by AWS.. charged for the FULL hour if YOU terminate your instance.
- Good for massively parallel computations, or high-compute batch jobs, due to the fact that you can get spot instances for often 50-90% less than on-demand instances, you can massively increase your compute capacity by 2-10x for the same budget.
- Reserved Instance - fixed compute, reserved for a certain period of time. Cheaper than on-demand if you have predictable long term usage.
- Dedicated Host - physical EC2 server available only to you. No shared. i.e. if a regulatory body says that you must not be using multi-tenant computing.
Instance startup and termination
When an EC2 instance is terminated, the root EBS volume is also deleted by default.
Termination Protection is off by default, and can be used to prevent accidental termination
On default AMIs, the EBS root volume can be encrypted via 3rd party softare, but not in the AWS console.
Use ’lsblk’ to get a list of mounted disks
To get the reason for an EC2 instance termination from the CLI, you can use teh following command: aws ec2 describe-instances* along with the terminated instance id. You will receive a response similar to the following
"StateReason" {
"Message": "Client.UserInitiatedShutdown: User initiated shutdown",
"Code": "Client.UserInitiatedShutdown"
}
Instance Lifecycle
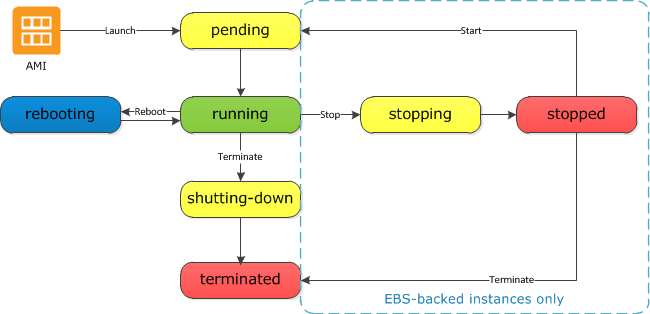
Stopping and starting instances
In most cases, the instance is migrated to a new underlying host computer when it’s started.
There are different types of AMI images
- HVM (Hardware Virutal Machine) EBS-Backed - supported by all instance types (T2, M4, etc)
- HVM Instance Store - supported by M3, C3, X3, R3, I2, D2
- PV (Paravirtual) EBS-Backed - supported by M3, C3
- PV Instance Store - Supported by M3, C3
A Golden Image is an image which you’ve customised to your liking with all the necessary software, configuration, etc ready to go and saved as a personal AMI, from which you can launch instances.
Instance Metadata
Available from the EC2 instances at the following URL: http://169.254.169.254/latest/meta-data/
Can get the instance IP address via: http://169.254.169.254/latest/meta-data/public/ipv4/
EBS (Elastic Block Storage)
EBS volumes appear as native block devices, similar to a hard drive of other physical device.
EBS volumes can only be scaled up, not down.
All EBS volumes can be changed on the fly, except for Magnetic (standard), however if you do this, you’ll need to wait 6 hours before making any further changes to the volume.
For changing a volume, the best practice is to first stop the EC2 instance it’s attached to.
Instance store volumes is sometimes called ’ephemeral storage’. If the underlying host fails or stops, all data will be lost. No data is lost on reboot.
When you create an EBS volume in an AZ, it it automatically replicated within that zone to prevent data loss due to the failure or any single hardware component.
EBS can’t tolerate an entire AZ failure - EBS volumes are only replicated within the AZ, so S3 recommends always keeping a snapshot of your EBS volumes in an S3 bucket for high durability.
If the root volume of an EC2 instance fails, and you need to recover data from it, you can:
- Detach the volume
- Attach it to another instance as a data volume
- Fix issues in the files, copy data out if necessary
- Re-attach to the original instance, and restart
Snapshots
Before taking a snapshot of an EBS volume that serves as a root device, you first need to stop the EC2 instance which it’s attached to.
While a snapshot is pending, it’s safe to use the EBS volume. An in-progress snapshot is not affected by reads and writes to the volume.
To change the type of a volume, first create a snapshot, then use the snapshot to create the new volume.
EBS volumes must be in the same AZ as the instance they’re attached to. To transfer between instances, snapshot the volume, and use it to create a new volume in the desired AZ.
Additional EBS volumes can be encrypted via the console.
Snapshots can be shared with other accounts, or shared in the AWS marketplace.
Snapshot backups
There are two types of snapshots supported:
- Point in time - single copy of entire volume
- Incremental
- The first snapshot can take some time to create, and will be large, as it’s backing up the entire volume
- Subsequent snapshots are smaller as only new or changed data is snapshotted
Snapshot encryption
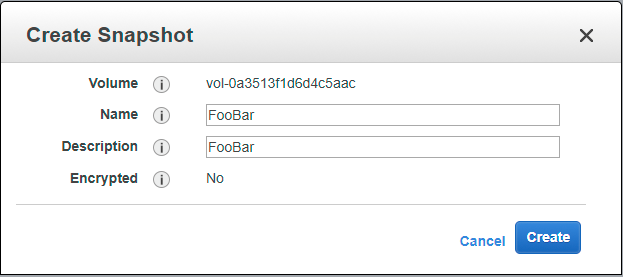
Can encypt snapshots via the ‘copy’ option; if you have an EC2 instance that has an unencrypted volume, and you want to create an encrypted volume from it:
- Create a snapshot of your unencrypted EBS volume. This snapshot will also be unencrypted.
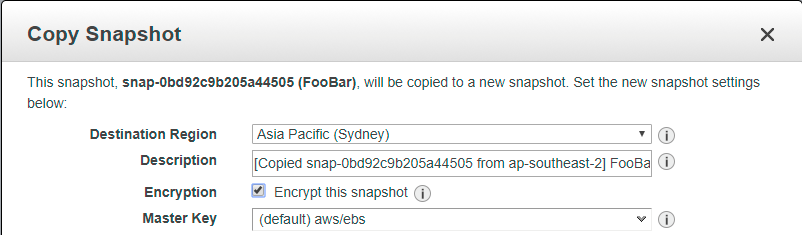
- Copy the snapshot, ensuring that the Encrypt this snapshot checkbox is checked
- Restore the encrypted snapshot to a new volume, which will also be encrypted
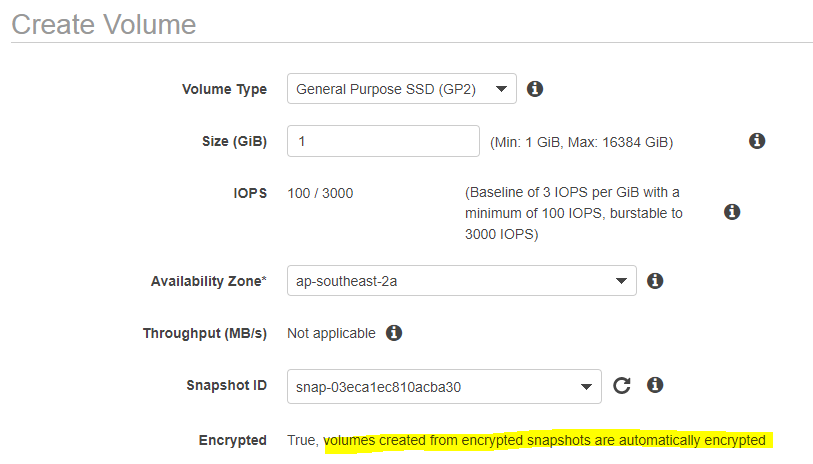
Snapshots of already encrypted volumes are encrypted automatically. Similarly, volumes restored from encrypted snapshots are encypted automatically.
Encrypted snapshots cannot be shared - the encyption key is tied to the AWS root account.
EBS Volume Types
General Purpose SSD (gp2)
The performance of GP2 volumes are tied to volume size - larger volumes perform better. 3 IOPS per GB, up to 1000 IOPS. Can burst up to 3000 IOPS for extended periods of time.
Bursting and I/O credits are only relevant for volumes under 1TB, where burst performance exceeds baseline performance. i.e. Burst is 3000 IOPS per second, baseline performance at 1TB is 3000 IOPS per second - you are always getting burst performance.
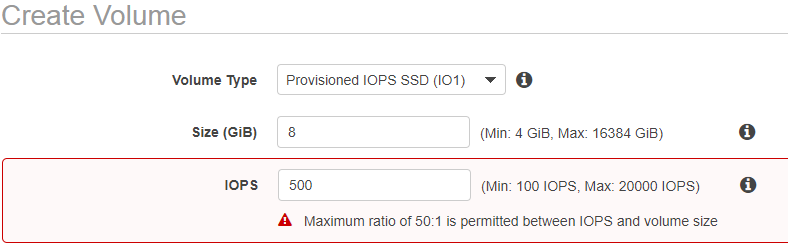
Provisioned IOPS SSD (io1)
Highest performance SSD. Intended for apps which require more than 10000 IOPS per volume or 160 MiB/s of throughput per volume.
IOPS must be between 100 and 20000.
The maximum ratio of between IOPS and Volume Size is 50:1. This means that for an 8GiB volume, you can have a max IOPS of 50*8 = 400 IOPS.
Throughput optimised magnetic (st1)
Cannot be a boot volume
Useful for:
- Frequently accessed data
- Big data
- Data warehousing
- Log processing
Cold HDD magnetic (sc1)
Cannot be a boot volume
Cheaper than st1, designed for infrequently accessed, large, sequential workloads
Magnetic (standard)
Magentic is one of the previous generation volumes, it’s recommended you use one of the newer volume types i.e. st1 or sc1, but may still be in the exam
RAID Arrays
To increase performance, it’s possible to configure EBS volumes as a RAID array.
| RAID # | |
|---|---|
| RAID 0 | Striped, no redundancy. |
| RAID 1 | Mirrored, has redundancy. |
| RAID 5 | Good for reads, bad for writes. Can rebuild RAID array if necessary. Note: AWS strongly discourages use of RAID 5. Do not fall for it in the exam. |
| RAID 10 | Striped and mirrored. Good reduncancy, and good performance. |
Generally use RAID 0 (no reduncancy) or RAID 10 (good redunancy)
Once you provision your EBS volumes for the EC2 instance, for Windows instances, RAID is convered via Disk Management in the instance itself.
Due to caching, and to prevent any I/O while the snapshot is being created, before taking a snapshot of a RAID array, you’ll need to:
- Freeze the file system
- Unmount the RAID array
- Shut down the EC2 instance
If you need to minimize the downtime while backing up RAIDed EBS volumes, you can:
- Suspend disk I/O
- Start the EBS snapshot of volumes
- Wait for snapshots to complete
- Resume disk I/O
Bootstrap scripts
Bootstrap scripts are set up in the EC2 user data, can be used to install PHP, etc on new EC2 instances.
i.e. a bootstrap script could look like:
#!/bin/bash yum update -y hum install yttpd -y service httpd start chkconfig httpd on aws s3 cp s3://...
Security
Logging in to an instance
Amazon EC2 uses public key cryptography to encrypt and decrypt login information.
To log in to your EC2 instance, you must create a key pair, and provide the private key when connecting to the instance.
Linux instances have no password and you must use a key pair when logging in via SSH.
For Windows instances, you use the key pair to obtain the administrator password, then log in using RDP.
SSH uses port 22, and RDP uses port 3389. If you can’t connect to your instance, check your Security Group and NACL configurations.
Security Groups and NACLs
Security Groups:
- Block all traffic by default; no traffic rules exist in a freshly created security group.
- Can be used for configuring inbound and outbound traffic rules. i.e. HTTP, SSH, etc.
- Changes are applied immediately.
- Are stateful. This means that inbound rules are also allowed out (unlike NACLs).
- Do not allow blocking of specific ip addresses (use NACs for this instead)
All instances in a security group can communicate with all other instances in that same security group by default.
To change the security group of an instance, right click on the instances, select ’networking’, and select ‘change security group’
It’s possible to have multiple security groups associated with an instance.
NACLs
- Are stateless. If you have inbound traffic - in order for responses to inbound traffic to be received, any inbound traffic rule will require a corresponding outbound rule.
Roles
It’s possible ot set role in instance creation and add/remove roles while the instance is running.
Using IAM roles means that you don’t need to store credentials (such as AWS Secret Key and Access Key) in the EC2 instance itself.
i.e. if you want to give your EC2 instance full access to S3, you can use the AmazonS3FullAccess IAM role. You can then run s3 commands such as ‘aws s3 ls’ within the EC2 instance.
IAM roles are created globally
Monitoring
There are two types of EBS monitoring:
- Basic Monitoring - available at no charge, and is enabled by default, with samples taken every 5 minutes
- Detailed Monitoring - can be enabled for a fee, reducing the sample time to 1 minute.
System status checks make sure that packets can reach the instance (checking hypervisor is up)
Instance status checks make sure that the operating system can accept traffic
Cloudwatch
Note that CloudWatch and CloudTrail are distinct products:
- CloudWatch - for performance monitoring and logging
- CloudTrail - for auditing i.e. when a new AWS role, user, etc is created. Stores all of it’s data in S3. - when enabling CloudTrail, you need to provide a S3 bucket where all logs can be written to.
Default metrics:
- CPU
- Network
- Disk
- Status Checks
Everything else is a custom metric. i.e. Memory is a custom CloudWatch metric.
Types of monitoring:
- Standard - sample every 5 minutes
- Detailed - sample every minute
Cloudwatch can be use for:
- Dashboards
- Alarms
- Events
- Logs
Cloudwatch supports the following alarm states:
- OK - the metric is within the threshold
- ALARM - The metric is outside the threshold
- INSUFFICIENT_DATA - The alarm has just started, but the metric is not available, or not enogh data is available for the metric to determine the alarm state
ELBs (Elastic Load Balancer)
ELB supports Perfect Forward Secrecy.
Types of ELB:

- Classic Load Balancer is the previous generation Load balancer for HTTP, HTTPS, and TCP traffic.
- Can load balance HTTP/HTTPS applications
- Can use layer 7-specific features such as X-Forwarded and sticky sessions
- Can also use strict layer 4 load balancing for applications that rely purely on the TCP protocol.
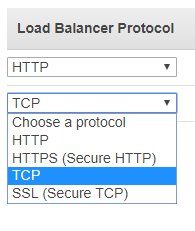
- When using the classic load balancer, you have the option of selecting which protocols it supports:
- Application Load Balancer is the current generation load balancer for HTTP, and HTTPS traffic.
- Can be used instead of the Classic Load Balancer when using exclusively HTTP/HTTPS traffic. Do not use if the aplication depends on the TCP protocol.
- Operates at the request level
- Made available half way through 2016.
- Network Load Balancer is the current generation load balancer when using exclusively TCP traffic.
- Can be used instead of the Classic Load Balancer when using TCP traffic.
- Operates at the connection level
- The Network Load Balancer is suitable when you need ultra-high performance, and have static IP addresses for your application.
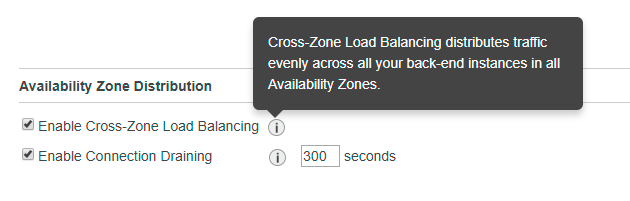
Cross-zone load balancing
By default, the Classic Load Balancer distributes traffic across all EC2 instances regardless of AZ. If you want to balance evenly across AZ, make sure you enable Cross-Zone load balancing:
More info on Cross-Zone load balancing
Make sure you remember to shut down your ELBs if you’re not using them
The major reason that people exceed the free tier is because they forgot to terminate their ELBs. It’s a good idea to tag your ELBs so that they can be tracked via resource groups.
ELBs initially have a DNS name, but no public IP address.
When an ELB is monitoring instances, the instance can have one of two status:
- In service
- Out of service
Set Evalate Target Health to true, and enable Latency Based Routing for HA (High Availability)
Auto scaling
Scaling Policy is a set of rules i.e. Increase if average CPU > 80% for a consecutive peroid of 5 minutes.
Desired Instances is adjusted based on the scaling policy, and won’t go below the miniumum or above the maximum size of the group.
Note that there is a default maximum of 20 running on-demand EC2 instances regardless of the min/max you set in your ASG scaling policies. You can request a limit increase by getting in touch with AWS… if your auto scaling triggers are firing, but you are not getting any more instances, check that you haven’t reached the default maximum.
Deleting an ASG will automatically delete any instances that it created.
Launch configurations cannot be modified after creation. If you need to make a change, create a new launch configation and update your auto scaling group to use it.
Launch configurations can belong to multiple Auto Scaling groups, however you can only specify one launch configuration at a time for an Auto Scaling group.
AMIs can be used with Auto Scaling groups.
More info on launch configurations
The following scale out options are available:
- Scheduled scaling - adjusting the size of a group at a specific time
- Dynamic scaling - via creating a scaling policy to automatically adjust the size of the group based on a specificed increase in demanc
- Manual scaling - via manually increasing the size of the group
More info on auto scaling lifecycles
To attach EC2 instances to an Auto Scaling group, ensure that:
- The instance is in the running state
- The AMIs used to launch the instance still exist
- The instance is not a member of another Auto Scaling group
- The instance is in the same AZ as the Auto Scaling group
More info on attaching instances to an Auto Scaling group
Auto Scaling Lifecycle and Lifecycle Hooks
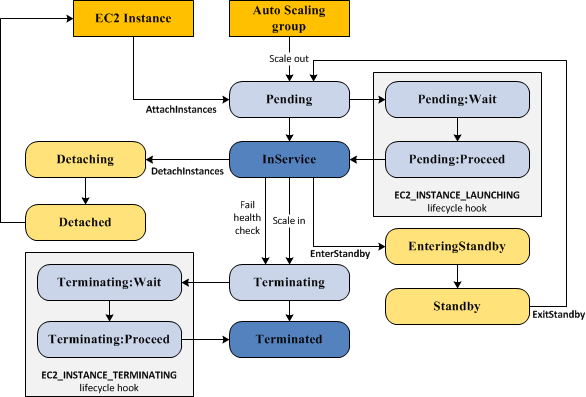
In the Pending:Wait state, no lifecycle policies take effect.
The cooldown period is the number of seconds after a scaling activity completes before another can start.
Auto Scaling Group Termination Policy
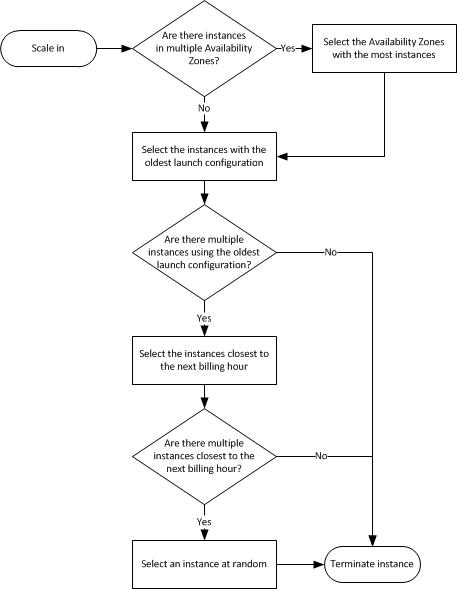
Placement Groups
Placement groups:
- Are a logical grouping of instances in a single AZ
- Cannot span multiple AZs
- Are good for grid computing or any time you need high throughput and very low network latency between your instances.
- Must have a unique name in your AWS account
- May only contain certain types of instances:
- Compute optimised
- GPU
- Memory optimised
- Storage optimised
- Work best when instance types within are homogenous - i.e. all compute optimised or all memory optimised
- Cannot be merged, however it is possible to move existing instances into placement groups
Elastic IP
An elastic IP is a public IPv4 address which is reachable from the internet. If your instance does not have a public IPv4 address, youc an associate an Elastic IP address with the instance.
IPv6 is not currently supported for Elastic IP.
There is no charge for Elastic IP addresses assuming the following are true:
- The Elastic IP address is associated with an Amazon EC2 instance
- The instance associated with the Elastic IP address is running
- The instance has only one Elastic IP address attached to it.
Otherwise, there is an hourly charge.
More info on Elastic IP address pricing
Elastic IP addersses annot be tagged
EFS (Elastic File System)
EFS:
- Supports NTFS v4
- Scales to petabytes
- Supports 1000’s of NFS connections
- Stores it’s data redundantly across multiple AZ’s
- Is File Based storage (not block based, or object based) - provides a file system interface and file system access sematics (i.e. strong consistency and file locking). You can think of EFS as a kind of NAS
Lambda
Lambda can respond to triggers/events from AWS core services i.e.
- Kinesis
- API Gateway requests
1 event = 1 function
Lambda is a serverless, managed service and scales up automatically:
- There are no servers to configure.
- You only need one set of code
- ELBs/ASGs/etc are not needed.
Language support:
- C#
- Java
- NodeJS
- Python
The first 1m requests are free, then $0.20 per 1m requests thereafter.
The max duration of a Lambda function is 5 minutes.
The minimum memory allocation is 128 MB, and maximum is 1536 MB, in 64MB increments. If the maximum memory use is exceeded, the function invocation will be terminated.
512MB of temp space is allocated per invocation when using Lambda functions.
With a lot of lambda functions communicating between each other, the architecture can easily become extremely complex. AWS X-Ray can help simplify Lambda debugging.
Lambda works globally, so can be used for things such as backing up a S3 bucket in one region to a different region.
Want to read more?
Check out the AWS Certified Solutions Architect Associate All-in-One Exam Guide on Amazon.com. The book getting great reviews, was updated to cover the new 2018 exam SAA-C01, and is available on Kindle and as a paperback book.
See my full exam tips here: AWS Solutions Architect Associate Exam Tips
And click here to see all of my notes: AWS Solutions Architect Associate Exam Notes
