AWS Solution Architect Associate Exam Study Notes: S3 (Simple Storage Service), CloudFront and Storage Gateway
- Oct 8, 2017
These notes were written while working through the A Cloud Guru AWS Certified Solutions Architect - Associate online course. These notes are partly from the videos, and also from various other online sources. Primarily, they’re notes for me, but you might find them useful too.
Since the AWS platform is changing so quickly, it’s possible that some of these notes may be out of date, so please take that into consideration if you are reading them.
Please let me know in the comments below if you have any corrections or updates which you’d like me to add.
This post was last updated in March, 2019.
S3 (Simple Storage Service)
S3 buckets are stored in specific regions, however bucket names must be globally unique.
S3 Supports:
- Versioning
- Encryption
- Static website hosting
- Access logs - server access logging can be used to track requests for access to your bucket, and can be used for internal security and access audits
An S3 object consists of:
- Key
- Value
- Version ID (used when versioning is turned on)
- Metadata (data about the object such as date uploaded)
- Subresources:
- ACLs (Access Control Lists i.e. who can access the file)
- Torrent
Charges
S3 charges for:
- The volume of data you have stored
- The number of requests
- Data transfer out (including to buckets in other zones/regions)
- Transfer Acceleration (which uses the AWS CloudFront CDN for caching files at edge locations)
Storage Class Tiers
S3 has:
- 99.99% availability
- 99.999999999% durability (11 9’s, you won’t lose a file due to S3 failure)
S3 IA (Infrequent Access):
- 99% availability
- 99.999999999% durability (11 9’s, you won’t lose a file due to S3 failure)
- Best for situations where you want lower costs than standard S3, and a file doesn’t need to be always accessable, but it’s critical that the file is not lost.
S3 RRS (Reduced Redundancy Storage) has:
- 99.99% availability
- 99.99% durability (so you may lose a file). This means that RRS is best for situations where you want lower costs than standard S3, and you’re storing non-critical data, or data which can be regenerated in the case where the file is lost.
S3 RRS is not advertised anymore, but may still be mentioned in the exam.
Glacier (which is not actually in the S3 family of services):
- Extremely cheap long term storage for archiving
- Retreival takes 3-5 hours to complete
- Has a 90 day minimum storage duration
- The first 10GB of data retreival per month is free
Note that Glacier is not supported by AWS import/export. In order to use this functionality, you must first restore it into S3 via the S3 Lifecycle Restore feature
Uploading to S3
200 OK is returned after a successful upload.
The minimum file size of an object is 0 bytes.
Multipart upload is supported via the S3 API. It’s recommended to always use multipart uploads for file sizes over 100mb.
S3 has:
- Atomic updates - you’ll never have a situation where a file is partly updated; it’ll either fully succeed (the file will be updated), or fully fail (the file will NOT be updated).
- Read after write consistency of PUTs for new objects; you can read an object immediately after upload.
- Eventual consistency for updates and DELETEs; an object won’t immediately be updated. If you try to access an object immediately after it’s been updated, you may get the old version. It takes a few seconds for an update or delete to propagate.
Access
The S3 bucket url format is: s3-region.amazonaws.com/bucketname/path-to-file i.e. https://s3-ap-southeast-2.amazonaws.com/lithiumdream-wpmedia2017/2017/10/8e30689cd04457e1a7b44d590b0edfc1.jpg or https://lithiumdream-wpmedia2017.s3-ap-southeast-2.amazonaws.com/2017/10/8e30689cd04457e1a7b44d590b0edfc1.jpg
{kind=link}
{kind=link}
If S3 is being used as a static website, the URL format will be: https://s3-website-ap-southeast-2.amazonaws.com/2017/10/8e30689cd04457e1a7b44d590b0edfc1.jpg or https://lithiumdream-wpmedia2017.s3-website-ap-southeast-2.amazonaws.com/2017/10/8e30689cd04457e1a7b44d590b0edfc1.jpg
{kind=link}
{kind=link}
Note s3-region.amazonaws.com vs s3-website.amazonaws.com
The default for permissions for objects on buckets is private.
In order to access a file via public DNS, you’ll need to make the file publically available.. Not even the root user can access the file via public DNS, without making the file publically available.
With ACLs (Access Control Lists), you can allow Read and/or Write access to both the objects in the bucket and the permissions to the object.
Bucket Policies override any ACLs - if you enable public access via a Bucket Policy, the object will be publically accessable regardless any ACLs which have been set up.
Buckets can be configured to log all requests. Logs can be either written to the bucket containing the accessed objects, or to a different bucket.
OAI (Origin Access Identity) can be used for allowing CloudFront to access objects in an S3 bucket, while preventing the S3 bucket itself from being publically accessable directly. This prevents anybody from bypassing Cloudfront and using the S3 url to get content that you want to restrict access to.
Encryption
Data in transit is encrypted via TLS
Data at rest can be encrypted by:
- Server-side encryption
- SSE-S3 - Amazon S3-Managed Keys where S3 manages the keys, encrypting each object with a unique key using AES-256, and even ecrypts the key itself with a master key which regularly rotates.
- SSE-KMS - AWS KMS-Managed Keys - Similar to SSE-S3, but with an option to provide an audit trail of when your key is used, and by whom, and also the option to create and manage keys yourself.
- SSE-C - Customer-Provided Keys - Where you manage the encryption keys, and AWS manages encryption and decryption as it reads from and writes to disk.
- Client Side Encryption
Storage
S3 objects are stored in buckets, which can be thought of as folders
Buckets are private by default
S3 buckets are suitable for objects or flat files. S3 is NOT suitable for storing an OS or Database (use block storage for this)
There is a maximum of 100 buckets per account by default.
S3 objects are stored, and sorted by name in lexographical order, which means that there can be peformance bottlenecks is you have a large number of objects in your S3 bucket which have similar names.
For S3 buckets with a large number of files, it’s recommended that you add a salt to the beginning of each file, to help avoid performance bottlenecks, and ensure that files are evenly distributed thoughout the datacenter.
S3 objects are stored in multiple facilities; S3 is designed to sustain the loss of 2 facilities concurrently.
There is unlimited storage available with support for objects with sizes from 0 bytes to 5TB.
Versioning
On buckets which have had versioning enabled - versioning can only be disabled, but not removed. If you want to get rid of versioning, you’ll need to copy files to a new bucket which has never had versioning enabled, and update any references pointing to the old bucket to point to the new bucket instead.
If you enable versioning on an existing bucket, versioning will not be applied to existing objects; versioning will only apply to any new or updated objects.
Cross-region replication requires that versioning is enabled.
Side note: Dropbox uses S3 versioning.
Lifecycle management
There is tiered storage available, and you can use lifecycle management to transition though the tiers. For example, there might be a requirement that invoices for the last 24 months are immediately available, and that older invoices don’t need to be immediately available, but must be stored for compliance reasons for 7 years. For this scenario, you may decide to keep the invoices younger than 24 months in S3 for immediate access, and use lifecycle management to move the invoices to Glacier (where storage is extremely cheap, with the tradeoff that it takes 3-5 hours to restore an object) for long term storage.
Lifecycle management also supports permanently deleting files after a configurable amount of time i.e. after the file has been migrated to Glacier.
Cloudfront
Cloudfront is AWS’s CDN.
Cloudfront supports Perfect Forward Secrecy.
Edge Locations
Edge locations are separate from and different to AWS AZ’s and Regions
Edge locations support:
- Reads
- Writes - enabling writes means that customers can upload files to their local edge location, which can speed up data transfer for them
Origin
The origin is the name of the source location
The origin can be:
- A S3 bucket
- An EC2 Instance
- An ELB
- Route53
- Outside of AWS
Distribution
A “distribution” is the collection of edge locations in the CDN
There are two different types of distribution:
- Web distribution - used for websites
- RTMP distribution - used for streaming content (i.e. video), and only supported if the origin is S3 - other origins such as EC2, etc do not support RTMP
It’s possible to clear cached items. If the cache isn’t cleared, all items live for their configured TTL (Time To Live)
Read access can be restricted via pre-signed urls and cookies. i.e. to ensure only certain customers can access certain objects.
Geo restrictions can be created for whitelists/blacklists
Storage Gateway
A Storage Gateway is a software appliance which sits in your data center, and securely connects your on-premise
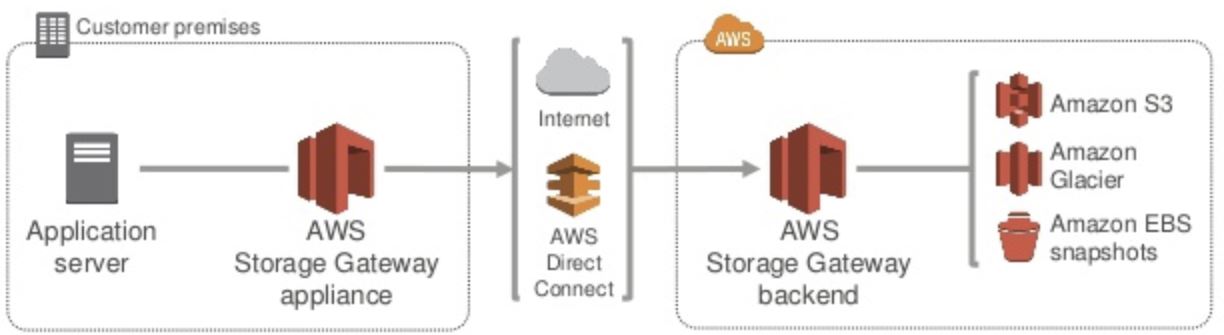
There are four types of Storage Gateway:
- File Gateway - using NFS to store files in S3
- Volume Gateway - a virtual iSCSI disk. Block based, not object based like S3.
- Cached volumes - the entire data set is stored on the cloud, with recently-read data on site, for quick retrieval of frequently accessed data.
- Stored volumes - similar to Volume Gateway, but the entire data-set is stored on-premise with data being incrementally backed up to S3
- Tape Gateway - virtual tapes, backed up to Glacier. Used by popular backup applications such as NetBackup
All data transferred between Storage Gateway and S3 is encrypted using SSL. By default, all data stored in S3 is encrypted server-side with SSE-S3, so your data is automatically encrypted at rest.
Want to read more?
Check out the AWS Certified Solutions Architect Associate All-in-One Exam Guide on Amazon.com. The book getting great reviews, was updated to cover the new 2018 exam SAA-C01, and is available on Kindle and as a paperback book.
See my full exam tips here: AWS Solutions Architect Associate Exam Tips
And click here to see all of my notes: AWS Solutions Architect Associate Exam Notes
